Overview
- Project funded by Prasar Bharati.
- Project duration- 2021 to 2029
- Deployment: https://pb.madhavlab.com
Description
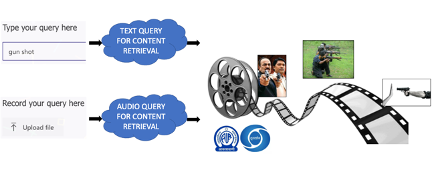
In this age of digitization and AI, machine learning technologies have created vast opportunities for content analysis—enabling better search, recommendation, accessibility, and translation.
In this project, we aim to develop and deploy audio-based content retrieval technologies for Prasar Bharati’s extensive multimedia archives. The goal is to make historical and cultural audio content more accessible through intelligent indexing and search.
We focus on two core retrieval methods:
- Audio Tagging: Automatically extracting meaningful text labels from audio.
- Audio Fingerprinting: Matching audio clips directly using acoustic similarity.
Objective
To develop AI-powered audio retrieval technologies that enable efficient access to large multimedia archives of Prasar Bharati through both audio and text queries.
Key Achievements & Impact
Core Technological Contributions:
-
Developed two key retrieval methods:
-
Audio Tagging: Extracting text labels from audio for search and indexing.
-
Audio Fingerprinting: Direct audio matching for fast retrieval of similar audio clips.
-
-
Built advanced AI models for audio event detection, query-by-example search, and interactive melody extraction.
Academic and Social Relevance:
-
Supports digitization and accessibility of archival multimedia content in India’s largest public broadcaster.
-
Facilitates faster, more accurate retrieval of historic and cultural content, making it accessible for educational and public use.
High-Impact Research Output:
-
8+ international publications in IEEE TASLP, ICASSP, ISMIR, ICLR, and CAI (2023–2024).
-
Open-source code repositories released for audio fingerprinting and query-by-example search, encouraging academic and industry adoption.
Dual Impact:
-
For Society: Helps Prasar Bharati unlock its vast audio archives for public engagement and historical preservation.
-
For Research: Advances the field of audio representation learning and retrieval techniques.
Publications
- Sagar Dutta and Vipul Arora, “AudioNet: Supervised Deep Hashing for Retrieval of Similar Audio Events”, in IEEE TASLP, 2024.
- Kavya Ranjan Saxena, and Vipul Arora, “Interactive singing melody extraction based on active adaptation”, in IEEE TASLP, 2024.
- Akanksha Singh, Vipul Arora, and Yi-Ping Phoebe Chen, “An efficient TF-IDF based Query by Example Spoken Term Detection”, in IEEE Conference on Artificial Intelligence (CAI), 2024.
- Akshay Raina, Sayeedul Islam Sheikh, and Vipul Arora, “Learning Ontology Informed Representations with Constraints for Acoustic Event Detection”, in IEEE ICASSP, 2024.
- Anup Singh, Kris Demuynck, and Vipul Arora, “Simultaneously Learning Robust Audio Embeddings and balanced Hash codes for Query-by-Example”, in IEEE ICASSP, 2023.
- Sumit Kumar, B. Anshuman, Linus Ruettimann, Richard H.R. Hahnloser and Vipul Arora, “Balanced Deep CCA for Bird Vocalization Detection”, IN IEEE ICASSP, 2023.
- Adhiraj Banerjee and Vipul Arora, “wav2tok: Deep Sequence Tokenizer for Audio Retrieval, In ICLR, 2023.
- Anup Singh, Kris Demuynck, and Vipul Arora, “Attention-Based Audio Embeddings for Query-by-Example”, In ISMIR, 2022.