Overview
- Project funded by MEITY
- Project duration: Mar 2022 to Mar 2026
Demos
- Say it to search it: voice search for NPTEL videos. youtube video
Description
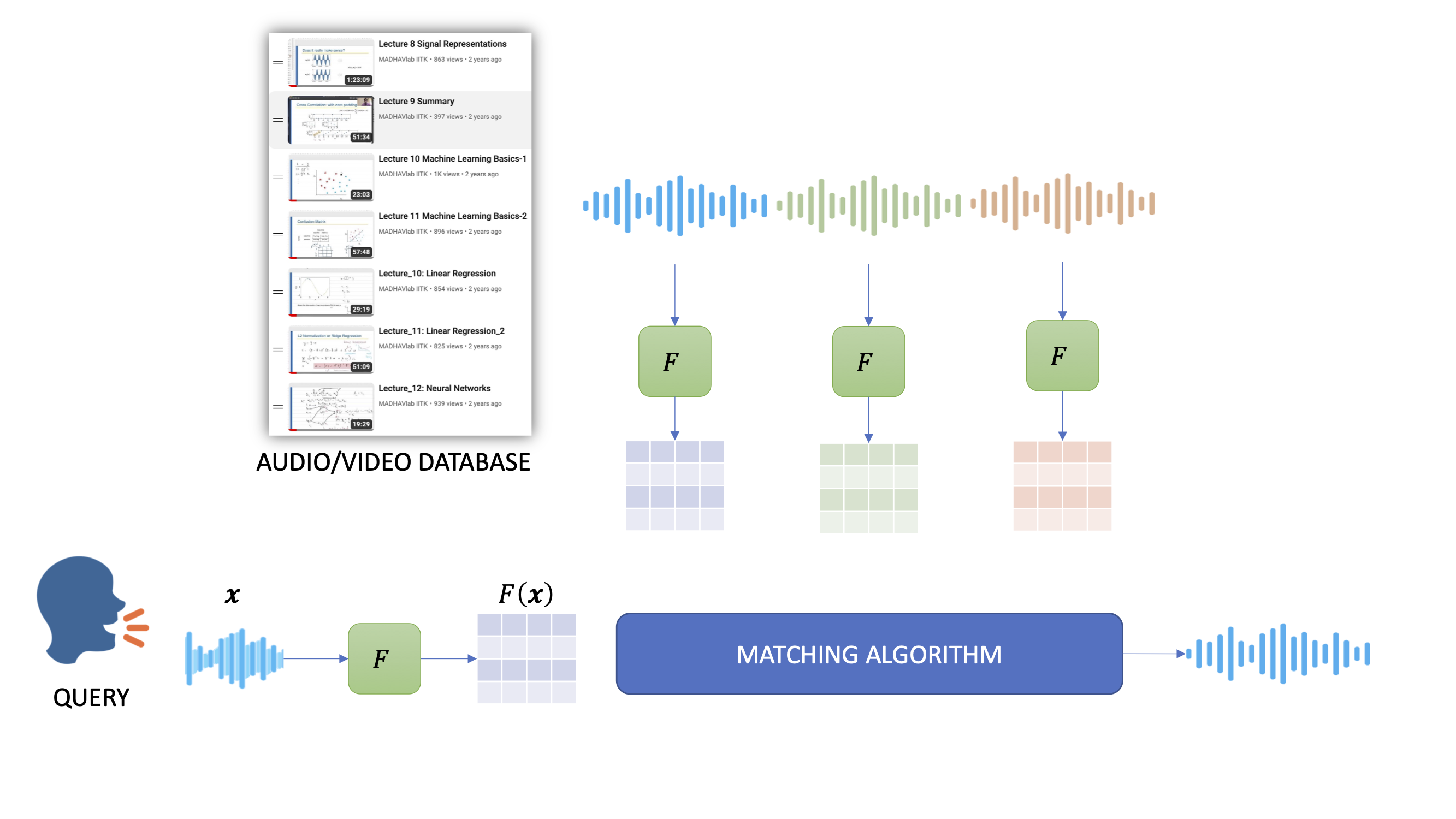
The goal of this project is to develop a system for spoken term detection (STD), i.e., to search a spoken query term in an audio database.The performance of the STD system depends critically on the representation of the speech signal. The acoustic waveforms, obtained by measuring sound pressure levels, of a word uttered by two different speakers look completely different and yet carry the same linguistic information. A good feature representation for STD should be speech-specific, and at the same time, it should be robust to the speaker and channel variability.
We will be developing two kinds of STD systems:
- Language dependent (works for a specific language)
- Language agnostic (works for any language)
The broader objective is to enable efficient, large-scale voice search across multiple Indian languages — without the need for text transcripts — to support applications in education, broadcasting, and public access services.
Key Achievements & Impact
Technological Breakthroughs:
-
Wav2Tok System: This is a language-agnostic Spoken Term Detection (STD) system with highly efficient audio search capabilities.
-
BEST-STD System: Developed a new encoder-based tokenizer with superior performance, reducing computational complexity and improving search accuracy across multiple Indian languages.
Public Tools and Community Engagement:
-
Public repositories released (GitHub, PyPI) for Wav2Tok and other tools, ensuring academic and industry-wide usability.
-
WiSSAP Cup Challenge organized to encourage student participation in speech processing, significantly improving student skill development in AI and ML domains.
Societal and Academic Impact:
-
Enhanced tokenization and search systems for low-resource Indian languages like Hindi, Bengali, Tamil, and Indian English, better than popular tokenizers such as wav2vec2, HuBERT and WavLM.
-
Demonstrated deployment-ready solutions for large-scale voice search (e.g., NPTEL, AIR news), which can be adapted for community services like voice-based information access.
-
Collaborative discussions are underway with startups for real-world deployment, contributing to the innovation ecosystem.
Capacity Building:
Trained multiple students (PhD and Master’s) in advanced AI research, leading to 4 international publications in prestigious conferences (ICLR, INTERSPEECH, ICASSP).
Summary of Societal Relevance:
This project directly contributes to Digital India goals by building inclusive technology for audio retrieval in Indian languages, supporting education, public information systems, and creating open-source tools for widespread use.
Publications
- Adhiraj Banerjee and Vipul Arora, “Wav2Tok: Deep Sequence Tokenizer for Audio Retrieval” in ICLR, 2023.
- Adhiraj Banerjee and Vipul Arora, “Enc-Dec RNN Acoustic Word Embeddings learned via Pairwise Prediction” in INTERSPEECH, 2023.
- Akansha Singh, Vipul Arora and Phoebe Chen, “An efficient TF-IDF based Query by Example Spoken Term Detection” in IEEE CAI, 2024.
Codes
- Text less model for audio tokenization and search: github link
- Audio tokenization and search using TF-IDF: github link
Summary
A project funded by MeitY under the BHASHINI initiative to empower Indian languages. It aims at developing voice search by tokenizing the speech and searching large speech databases with a speech-based query (say it to search it). The system we developed is language-agnostic and is tested across multiple Indian languages (seen and unseen). It does not require a written form of language, even for training.