Overview
- Project funded by MEITY
- Project duration: Mar 2022 to Mar 2025
Demos
- Say it to search it: voice search for NPTEL videos. youtube video
Description
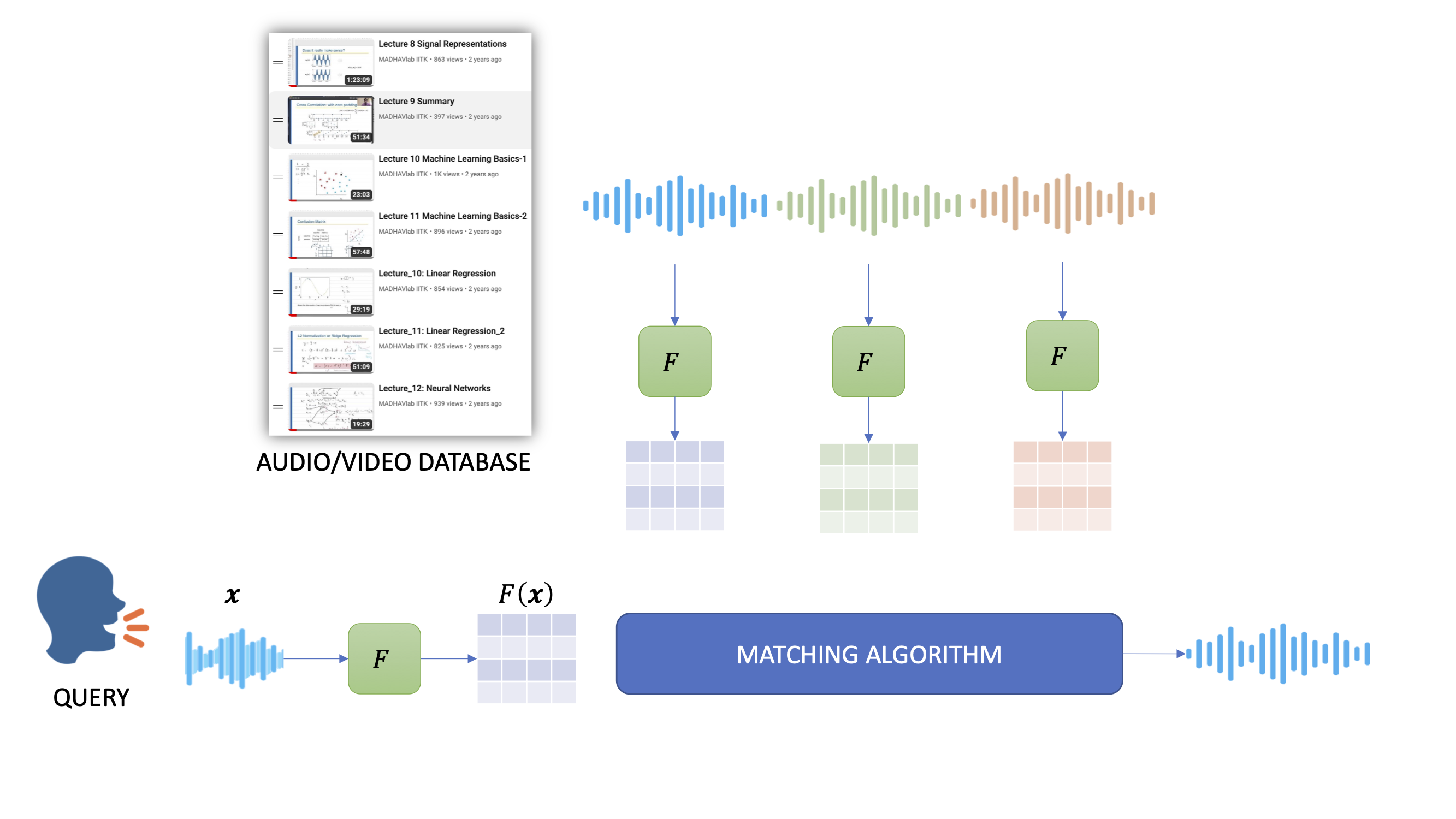
The goal of this project is to develop a system for spoken term detection (STD), i.e., to search a spoken query term in an audio database.The performance of the STD system depends critically on the representation of the speech signal. The acoustic waveforms, obtained by measuring sound pressure levels, of a word uttered by two different speakers look completely different and yet carry the same linguistic information. A good feature representation for STD should be speech-specific, and at the same time, it should be robust to the speaker and channel variability.
We will be developing two kinds of STD systems:
- Language dependent (works for a specific language)
- Language agnostic (works for any language)
Publications
- Adhiraj Banerjee and Vipul Arora, “Wav2Tok: Deep Sequence Tokenizer for Audio Retrieval” in ICLR, 2023.
- Adhiraj Banerjee and Vipul Arora, “Enc-Dec RNN Acoustic Word Embeddings learned via Pairwise Prediction” in INTERSPEECH, 2023.
- Akansha Singh, Vipul Arora and Phoebe Chen, “An efficient TF-IDF based Query by Example Spoken Term Detection” in IEEE CAI, 2024.
Codes
- Text less model for audio tokenization and search: github link
- Audio tokenization and search using TF-IDF: github link